
Si tu te reconvertis dans le développement web ou que tu débutes ta carrière de développeur, tu vas rapidement tomber sur le terme CI/CD. Dans les offres d'emploi, dans les discussions d'équipe, dans les tutoriels avancés. Et souvent, personne ne prend le temps d'expliquer ce que c'est vraiment, dans la vie de tous les jours. Cet article est là pour combler ce manque.
Le problème que CI/CD résout
Imagine que tu travailles dans une équipe de développeurs. Chacun bosse sur sa partie du projet, sur sa propre branche de code. Tout se passe bien tant que vous travaillez séparément. Mais le jour où il faut tout assembler et envoyer ça en production... c'est souvent le chaos.
Un développeur a changé une fonction que l'autre utilisait. Un autre a mis à jour une dépendance qui casse l'environnement de son voisin. Et personne ne s'en est rendu compte avant le moment fatidique du déploiement. Résultat : une journée de débogage en urgence, des nerfs à vif, et des utilisateurs qui voient une application cassée.
Ce scénario, les équipes l'ont vécu des centaines de fois. La réponse que l'industrie a trouvée, c'est d'automatiser tout ce qui peut l'être, et de le faire en continu plutôt qu'en une seule grosse opération stressante en fin de sprint.
C'est exactement l'idée derrière CI/CD.
CI, CD, CD : trois sigles pour une seule idée
CI/CD regroupe en réalité trois concepts distincts. Voici ce qu'ils veulent dire.
L'intégration continue (CI)
La Continuous Integration, ou intégration continue, c'est le principe de fusionner le code de chaque développeur très régulièrement dans une branche principale commune, et de lancer automatiquement des tests à chaque fois que quelqu'un pousse du code.
Concrètement : tu écris ton code, tu le pousses sur GitHub (ou GitLab, Bitbucket, peu importe). En quelques secondes, un système automatique récupère ton code, le compile, lance une batterie de tests, et te dit si quelque chose est cassé.
L'objectif ? Trouver les problèmes tôt, quand ils sont encore faciles à corriger, plutôt que deux semaines plus tard quand tout le monde a avancé sur autre chose.
La livraison continue (CD)
La Continuous Delivery, ou livraison continue, va un cran plus loin. Si tous les tests passent, le code est automatiquement préparé et déployé sur un environnement de test (souvent appelé staging) qui ressemble à la production réelle.
À ce stade, un humain reste dans la boucle : quelqu'un valide manuellement avant que le code parte vraiment en production. Mais le gros du travail (compilation, packaging, déploiement sur staging, tests complémentaires) est fait automatiquement.
Le déploiement continu (aussi CD)
Le Continuous Deployment, c'est le niveau maximal. Si les tests passent en staging, le code part directement en production sans intervention humaine. Aucun bouton à cliquer, aucune validation manuelle.
C'est le modèle qu'utilisent des entreprises comme Amazon ou Netflix, qui déploient des centaines de fois par jour. Ce n'est pas adapté à tout le monde, mais c'est l'horizon vers lequel beaucoup d'équipes cherchent à tendre.
En résumé : CI = on teste en continu. Continuous Delivery = on prépare en continu mais on valide manuellement. Continuous Deployment = on livre en continu sans intervention humaine. Le pipeline, lui, reste le même dans les trois cas. Ce qui change, c'est jusqu'où on laisse l'automatisation aller.
Comment fonctionne un pipeline CI/CD en pratique
Un pipeline, c'est une suite d'étapes que l'ordinateur exécute dans l'ordre, à ta place, dès qu'un événement se produit (en général, un push sur la branche principale). Voici ce que ça donne dans la vraie vie.
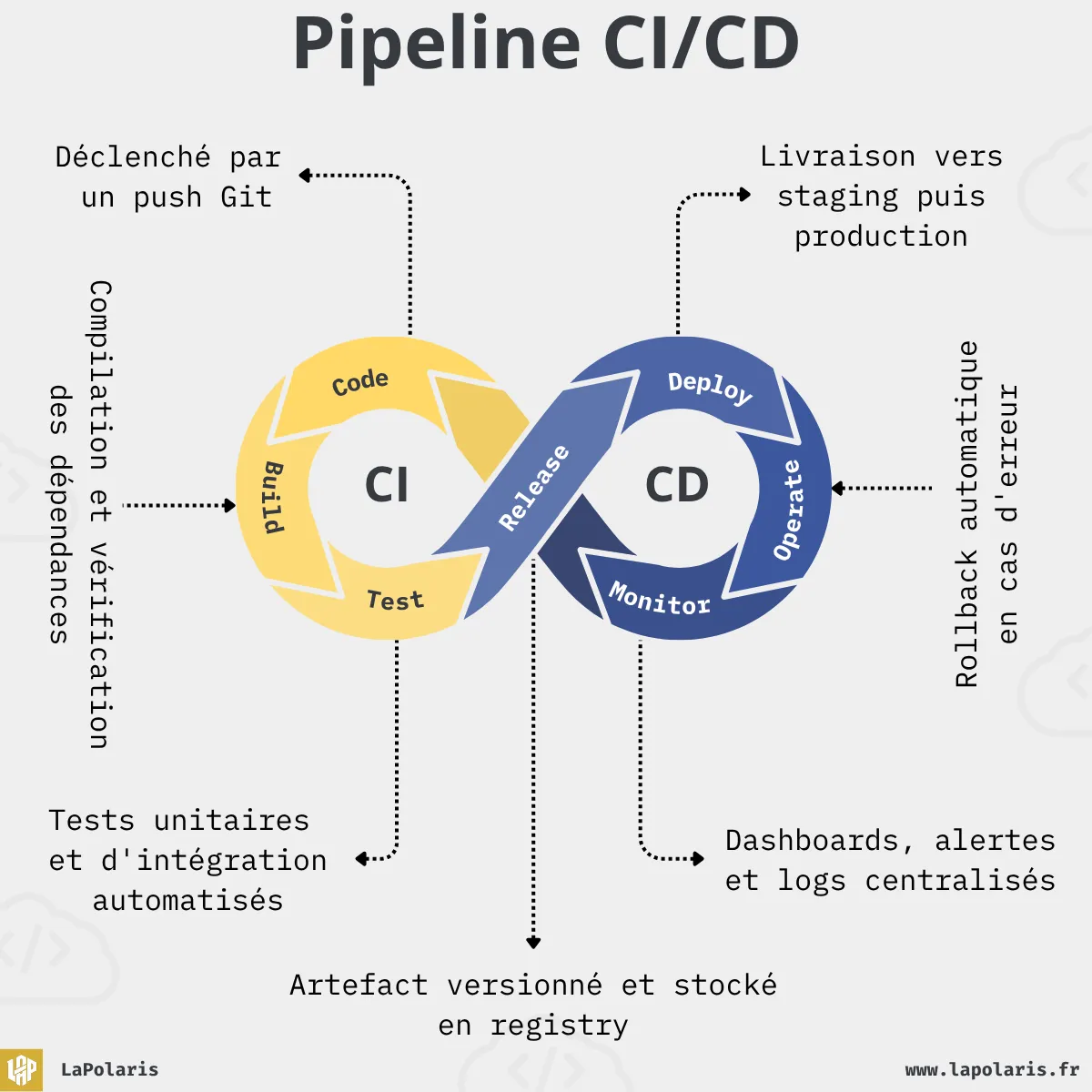
Étape 1 : le déclencheur
Tu pousses du code sur main, ou tu ouvres une pull request. C'est suffisant pour déclencher le pipeline automatiquement. Ton serveur CI (GitHub Actions, GitLab CI, Jenkins, CircleCI...) reçoit l'événement et lance les étapes suivantes.
Étape 2 : la construction et les tests rapides
Le pipeline récupère ton code et lance les vérifications de base :
- Les tests unitaires : ils vérifient que chaque petite brique de ta logique fonctionne correctement de façon isolée. Si ta fonction de calcul de prix retourne un mauvais résultat, c'est ici que tu le sauras.
- Les tests de fumée (smoke tests) : une poignée de vérifications rapides pour s'assurer que l'application se lance correctement et que les fonctions critiques répondent.
- L'analyse statique : le linter scanne ton code à la recherche d'erreurs de syntaxe, de failles de sécurité connues, de types incorrects. Aucune exécution du code, juste une lecture intelligente.
Si une de ces étapes échoue, le pipeline s'arrête immédiatement. Personne ne peut merger du code cassé sur la branche principale.
Étape 3 : l'artefact
Si tout passe, le pipeline construit un artefact : c'est le résultat packagé de ton code, prêt à être déployé. Ça peut prendre la forme d'une image Docker, d'un fichier JAR, d'un bundle JavaScript ou d'un package npm selon le type de projet.
Cet artefact est stocké dans un registre. L'avantage, c'est que le même artefact sera utilisé pour le déploiement en staging et en production. On évite ainsi les surprises du type "ça marche sur mon ordinateur mais pas sur le serveur".
Étape 4 : le déploiement en staging
L'artefact est déployé sur un environnement qui imite la production. C'est là que les tests plus lourds entrent en jeu : tests d'intégration (est-ce que les différents services communiquent bien ensemble ?), tests de performance (est-ce que l'application tient la charge ?), tests end-to-end (est-ce qu'un utilisateur peut réellement passer commande de bout en bout ?).
Étape 5 : la mise en production
Selon le niveau d'automatisation choisi, soit quelqu'un approuve manuellement le déploiement en production, soit le pipeline le fait tout seul si staging est au vert.
Les équipes avancées utilisent des stratégies de déploiement pour limiter le risque :
- Blue-green : deux environnements de production coexistent. Le trafic est basculé de l'ancien vers le nouveau d'un coup, et on peut revenir en arrière instantanément si quelque chose cloche.
- Canary : on envoie d'abord 5% du trafic vers la nouvelle version. Si les métriques restent bonnes, on monte progressivement à 100%.
Étape 6 : la surveillance et le rollback
Une fois en production, des outils de monitoring surveillent en permanence les erreurs, la latence, et les métriques métier. Si quelque chose déraille, deux options : on revient à la version précédente (rollback) ou on pousse un correctif rapide à travers le même pipeline (roll forward).
Ce que ça change vraiment au quotidien
Mettre en place un bon pipeline CI/CD ne se résume pas à livrer plus vite. Ça change fondamentalement la façon dont une équipe travaille.
Le feedback est immédiat. Tu introduis un bug, tu le sais en quelques minutes, pas deux semaines plus tard. Plus le retour est rapide, moins la correction est coûteuse en temps et en nerfs.
Les mises en production deviennent banales. Quand chaque changement passe par le même processus automatisé, déployer devient un acte ordinaire. Plus de "journée de release" à préparer pendant des jours.
On avance en petits pas. Au lieu de livrer un gros paquet de fonctionnalités une fois par mois, on livre de petites incréments régulièrement. Si quelque chose casse, c'est facile d'identifier quoi et pourquoi.
La confiance pour refactorer augmente. Quand le pipeline vérifie automatiquement que tout fonctionne encore après tes modifications, tu oses nettoyer et améliorer le code existant au lieu de le laisser se dégrader par peur de casser quelque chose.
Les vrais coûts à anticiper
CI/CD n'est pas gratuit, et c'est important de le savoir avant de se lancer. Les coûts sont réels, mais la plupart sont concentrés au début.
Le pipeline lui-même prend du temps à construire. Configurer les outils CI, écrire les scripts de déploiement, paramétrer l'infrastructure-as-code... c'est un investissement qui peut prendre plusieurs jours sur un projet neuf.
La qualité des tests conditionne tout. Un pipeline CI/CD n'est solide que si les tests qu'il exécute le sont aussi. Des tests flaky (qui passent une fois sur deux sans raison) ou des tests qui ne testent rien d'utile donnent un faux sentiment de sécurité. C'est souvent la partie la plus difficile à maintenir sur le long terme.
L'organisation doit changer. CI/CD brise l'ancienne logique du "je code, je balance à l'ops, c'est son problème". Dev, QA et Ops partagent désormais la responsabilité de la qualité. Ce n'est pas toujours une transition facile culturellement.
Quand CI/CD complet n'est pas adapté
Il y a des situations où un pipeline entièrement automatisé est clairement surdimensionné :
- Un prototype solo sur lequel tu itères rapidement, avec des déploiements rares.
- Un système legacy très stable qui ne change quasiment jamais.
- Un domaine réglementé (médical embarqué, aéronautique) où chaque release nécessite une validation formelle externe.
Dans ces cas, une CI basique (build + tests unitaires à chaque commit) reste utile sans qu'il soit nécessaire de mettre en place toute la machinerie de déploiement automatisé.
Par où commencer quand on débute
Si tu découvres tout ça, la bonne nouvelle c'est que tu n'as pas à tout faire en même temps. La progression naturelle ressemble à ça :
D'abord, mets en place la CI. Configure un workflow GitHub Actions (ou équivalent) qui compile ton projet et lance tes tests unitaires à chaque push. C'est la fondation de tout le reste, et ça apporte déjà beaucoup de valeur immédiatement.
Ensuite, ajoute un staging automatique. À chaque fois que la CI passe au vert, déploie automatiquement sur un environnement de test. Tu auras enfin un endroit fiable pour tester les nouvelles fonctionnalités dans des conditions proches du réel.
Enfin, automatise la production progressivement. Commence par exiger une approbation manuelle dans le pipeline avant le déploiement en prod. Avec le temps, quand tu fais confiance à tes tests et à ton monitoring, tu pourras envisager le déploiement entièrement automatisé.
Un signal utile : si le jour où tu dois déployer en production tu ressens encore une légère angoisse, c'est que ton pipeline n'est pas encore où il devrait être. Un bon CI/CD rend le déploiement aussi anodin qu'un commit.
Ce que les recruteurs attendent de toi sur ce sujet
En tant que développeur junior ou en reconversion, on ne va pas te demander de concevoir un pipeline CI/CD de A à Z dès le premier jour. Par contre, les recruteurs attendent que tu comprennes le concept, que tu saches lire un fichier de configuration GitHub Actions sans paniquer, et que tu ne déploies pas du code directement en production sans passer par le processus en place.
Dans les premières semaines dans une équipe, tu vas croiser des termes comme "le pipeline est rouge", "la PR bloque la CI", "ça passe pas en staging". Comprendre ces phrases et savoir comment réagir, c'est exactement ce que cet article t'a donné.
Pour aller plus loin dans la pratique, le plus simple est de créer un projet perso sur GitHub et de configurer un workflow GitHub Actions. Même basique, même juste pour lancer npm test à chaque push : tu auras mis le pied dans l'engrenage, et la progression vient naturellement ensuite.
Le CI/CD est l'un de ces sujets qui semblent abstraits jusqu'au moment où tu vois ton premier pipeline passer au vert tout seul après un push. A partir de là, on comprend vite pourquoi les équipes sérieuses ne s'en passent plus.
Tu veux aller plus loin et maîtriser Git et GitHub en pratique ?
LaPolaris propose une formation Git et GitHub : gestion de versions pour débutants sur 2 jours. Idéale si tu débutes ou que tu te reconvertis dans le développement. Sessions en présentiel à Brest ou à Paris, et à distance.
Voir la formation Git et GitHubQuestions fréquentes sur le CI/CD
Faut-il connaître le CI/CD pour un premier poste de développeur ?
Pas besoin de savoir le configurer de zéro, mais comprendre ce que c'est est clairement attendu. Dans la plupart des équipes, tu vas interagir avec un pipeline dès la première semaine : merger une PR, lire un log d'erreur CI, attendre que le staging soit déployé. Savoir de quoi on parle évite de paraître dépassé lors des entretiens ou des premiers jours en poste.
Quelle est la différence entre GitHub Actions et Jenkins ?
Les deux servent à exécuter des pipelines CI/CD, mais ils ne s'adressent pas au même contexte. GitHub Actions est intégré directement dans GitHub, sans installation, avec une configuration en YAML. C'est le choix naturel pour un projet hébergé sur GitHub, surtout quand on débute. Jenkins est un outil plus ancien, très puissant, mais qui demande une infrastructure propre et une configuration plus lourde. On le croise surtout dans les grandes entreprises avec des besoins très spécifiques.
Est-ce qu'on peut faire du CI/CD sur un projet personnel solo ?
Tout à fait, et c'est même recommandé pour apprendre. GitHub Actions est gratuit pour les repos publics et offre un quota généreux pour les repos privés. Configurer un workflow qui lance tes tests à chaque push prend moins d'une heure et te donne une vraie expérience concrète à mentionner en entretien. C'est souvent comme ça qu'on comprend réellement comment ça fonctionne.
Git et CI/CD, c'est la même chose ?
Non, mais les deux sont étroitement liés. Git est un outil de gestion de versions : il te permet de sauvegarder l'historique de ton code, de travailler sur des branches et de collaborer sans écraser le travail des autres. Le CI/CD, lui, se déclenche justement à partir des événements Git (un push, une pull request). Git est la fondation, CI/CD est ce qu'on construit dessus pour automatiser la suite. Maîtriser Git est donc un prérequis naturel avant d'aborder le CI/CD.


