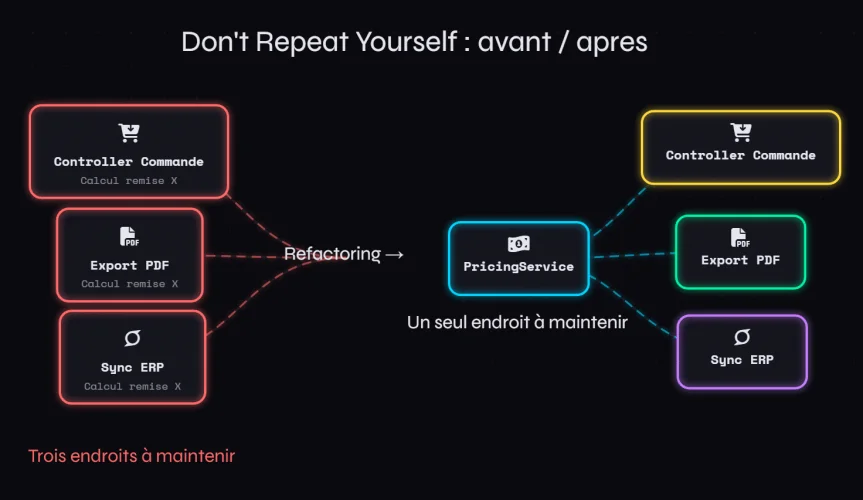
Imaginez ce scenario. Vous reprenez un projet PHP vieux de deux ans. Le client vous signale que le calcul de remise commerciale est faux. Vous cherchez dans le code et vous trouvez la logique de calcul a trois endroits distincts : dans le controller de commande, dans le service d'export PDF, et dans le script de synchronisation avec le ERP. Trois implementations, trois bugs potentiels, trois endroits a modifier a chaque evolution metier.
C'est precisement ce que le principe DRY, Don't Repeat Yourself, cherche a prevenir. Pas une philosophie abstraite, pas un objectif de perfection academique. Un outil pratique pour eviter que votre base de code devienne un piege a maintenance.
Cet article part de cas concrets pour expliquer comment appliquer DRY de facon utile, et surtout comment eviter de le mal appliquer, ce qui est aussi frequent que de ne pas l'appliquer du tout.
Ce que DRY signifie
La definition originale vient du livre The Pragmatic Programmer, publie par Andrew Hunt et David Thomas en 1999. La formulation exacte est : "Every piece of knowledge must have a single, authoritative, unambiguous representation within a system."
Le mot important ici, c'est connaissance. Pas code. DRY ne dit pas qu'on ne peut jamais ecrire deux boucles for dans un projet. Il dit qu'une regle metier, une contrainte, une formule, une politique de l'application doit exister a un seul endroit.
La confusion entre "ne pas copier-coller du code" et "ne pas dupliquer de la connaissance" est a l'origine de beaucoup d'abstractions forcees qui rendent le code plus difficile a lire qu'avant. Deux blocs de code qui se ressemblent peuvent representer deux connaissances differentes. Les regrouper par forme plutot que par sens est une erreur.
Exemple concret : une fonction qui valide un email pour l'inscription et une autre qui valide un email pour la mise a jour du profil peuvent avoir le meme code aujourd'hui. Mais elles peuvent evoluer independamment demain si les regles metier divergent. Les forcer dans une seule abstraction peut creer une rigidite artificielle.
Le probleme que DRY resout
Revenons au cas de la remise commerciale. La vraie douleur, c'est quand la regle change. Le service commercial decide que les remises applicables aux grands comptes passent de 15% a 18%. Vous mettez a jour le controller de commande. Vous oubliez le script de synchronisation ERP. Deux semaines plus tard, les exports PDF sont encore a l'ancien taux et personne ne s'en est rendu compte avant qu'un client le signale.
DRY n'est pas un principe de style. C'est une strategie de resilience face aux changements metier inevitables.
La solution DRY dans ce cas est simple : extraire la logique de calcul de remise dans un service dedie, une classe ou une fonction pure, et appeler cet endroit unique depuis tous les contextes qui en ont besoin.
Quand la regle change, vous modifiez un seul endroit. Vous ne risquez pas d'en oublier un. Vos tests unitaires ciblent ce point unique. Le contrat est clair.
Formes concrets de duplication a eliminer
1. La duplication de logique metier
C'est le cas le plus evident. Une formule de calcul, une condition de validation, un seuil, une regle d'eligibilite dupliques dans plusieurs fichiers. Chaque copie est une bombe a retardement. La solution est d'extraire dans un service, un helper, un trait, ou une classe metier selon l'architecture choisie.
En Symfony par exemple, un service PricingService injecte via l'autowiring peut centraliser toutes les regles de tarification. Un seul endroit a tester, un seul endroit a modifier.
2. La duplication de configuration
Les constantes magiques dispersees dans le code sont une forme de duplication moins visible mais tout aussi dangereuse. Un timeout de 30 secondes ecrit en dur a cinq endroits differents. Le jour ou on passe a 45 secondes, combien en oublie-t-on ?
La correction est simple : une constante nommee dans un fichier de configuration centralie, ou une variable d'environnement. Le nom donne du sens, la centralisation donne de la fiabilite.
3. La duplication de structure de donnees
Definir la meme structure deux fois, meme dans des langages differents, est une forme de duplication souvent ignoree. Un schema de validation cote backend en PHP et le meme schema reecrit en JavaScript cote frontend. Quand un champ est renomme cote serveur, le formulaire casse silencieusement.
Les solutions varient selon le contexte : generation de types TypeScript depuis le schema backend, contrats d'API partages, ou schema JSON Schema utilise des deux cotes. L'objectif est que la source de verite soit unique.
4. La duplication dans les tests
Les tests trop verbeux avec beaucoup de setup copie-colle entre methodes de test sont egalement une forme de violation DRY. Des fixtures partages, des factories de donnees de test, ou des methodes setUp bien concues reduisent la friction et rendent les tests plus lisibles.
Quand DRY devient un probleme
Appliquer DRY mecaniquement sur toute ressemblance de code produit ce qu'on appelle parfois une abstraction prematuree. Et une mauvaise abstraction est souvent pire qu'une duplication franche.
Le scenario classique : deux fonctions qui font la meme chose aujourd'hui. Quelqu'un les regroupe dans une fonction commune avec des parametres pour gerer les cas speciaux. Six mois plus tard, les deux usages ont evolue differemment, la fonction commune accepte huit parametres, dont certains annulent l'effet d'autres, et plus personne ne comprend ce qu'elle fait vraiment.
A garder en tete
Deux bouts de code qui se ressemblent par coincidence ne sont pas la meme connaissance. Avant de les fusionner, demandez-vous : si l'un d'eux change demain pour des raisons metier, est-ce que l'autre doit changer aussi ? Si la reponse n'est pas evidente, la duplication est peut-etre preferable.
Sandi Metz, developpeuse Ruby connue pour ses travaux sur la conception orientee objet, a formule ca simplement : la duplication est beaucoup moins chere que la mauvaise abstraction. Une phrase qui merite d'etre relue avant chaque refactoring.
Ce n'est pas une excuse pour ne pas appliquer DRY. C'est une mise en garde contre son application aveugle. Le jugement compte autant que la regle.
La methode pratique : rule of three
Une heuristique utile pour decider quand agir : la regle de trois. La premiere fois qu'on ecrit quelque chose, on l'ecrit simplement. La deuxieme fois qu'on a besoin de la meme chose, on le remarque mais on peut encore dupliquer. La troisieme fois, on refactorise.
Ce n'est pas une loi absolue, mais elle evite deux pieges opposes : abstraire trop tot sur la base d'une seule occurrence, ou ne jamais abstraire parce qu'on manque de recul.
En pratique, cela signifie aussi qu'un code review est un bon moment pour reperer les violations DRY. Quand on voit une logique deja presente ailleurs dans la base de code, c'est le moment d'en parler. Pas pour bloquer la PR, mais pour planifier le refactoring.
Les outils d'analyse statique peuvent aussi aider. Des outils comme PHP Copy/Paste Detector (phpcpd) ou SonarQube detectent automatiquement les blocs de code dupliques au-dela d'un certain seuil. Ils ne remplacent pas le jugement humain, mais ils pointent vers les zones a examiner.
DRY et les couches d'architecture
DRY interagit directement avec les decisions d'architecture. Dans une application Symfony, la separation en couches Controller / Service / Repository n'est pas seulement une question d'organisation. Elle est aussi une application du principe DRY a l'echelle architecturale.
Si la logique metier est dans les controllers, elle sera dupliquee des qu'un second point d'entree en a besoin : une commande CLI, une API REST, un webhook. Placer cette logique dans des services permet de l'appeler depuis n'importe quel contexte sans duplication.
De la meme facon, les repositories centralisent les requetes base de donnees. Si la logique de filtrage d'un listing est dans le controller, chaque nouveau point d'entree qui a besoin du meme listing doit copier cette logique ou l'appeler indirectement. Un repository bien concu expose des methodes metier (findActiveUsersByRegion plutot que des requetes SQL brutes) et respecte DRY au niveau des acces aux donnees.
En Python et Django, les memes principes s'appliquent avec les managers de modeles, les serializers, et les permissions classes. Le contexte change, le raisonnement reste le meme.
Ce que DRY change au quotidien
Les effets concrets d'une base de code qui respecte DRY ne sont pas spectaculaires au jour le jour. Ils se mesurent sur le long terme et particulierement dans les moments de stress : un bug en production a corriger rapidement, une evolution metier urgente a livrer, un nouveau developpeur qui rejoint le projet.
Un code DRY se modifie en un seul endroit et la correction se propage partout. Un code non-DRY necessite une recherche exhaustive avant chaque modification, avec le risque permanent d'en oublier. La difference de charge cognitive est significative.
Les tests sont aussi plus simples. Une logique centralisee se teste une seule fois. Une logique dupliquee necessite autant de tests que d'occurrences, et en pratique certaines ne sont pas testees, ce qui cree des angles morts.
Enfin, l'onboarding est facilite. Un nouveau venu sur le projet peut faire confiance a un service bien nomme. Il n'a pas besoin de verifier si la logique presente dans le service est identique a celle dans le controller, parce qu'il n'y a qu'un endroit ou cette logique existe.
Les limites a connaitre
DRY n'est pas gratuit. L'extraction et l'abstraction ajoutent de l'indirection. Pour lire le code, il faut naviguer entre plusieurs fichiers. Dans une petite application ou un script utilitaire, cette indirection peut etre un cout superieur au benefice.
Il y a aussi une tension entre DRY et le principe DAMP dans les tests (Descriptive And Meaningful Phrases). Les tests tres DRY avec beaucoup d'abstractions partagees peuvent devenir difficiles a diagnostiquer quand ils echouent. Un test un peu plus verbeux mais completement autonome est parfois plus utile qu'un test compact qui depend de dix fixtures partagees.
Le jugement contextuel reste indispensable. DRY est un outil, pas une religion. Il s'applique avec d'autres principes : YAGNI (You Aren't Gonna Need It) qui conseille de ne pas abstaire ce dont on n'a pas encore besoin, et KISS (Keep It Simple, Stupid) qui rappelle que la complexite a un cout reel sur la maintenabilite.
Par ou commencer sur un projet existant
Sur un projet deja en place avec des violations DRY historiques, la bonne strategie n'est pas de tout refactoriser d'un coup. C'est de traiter les violations au contact, au fur et a mesure que les zones concernees sont touchees pour d'autres raisons.
Quand vous corrigez un bug dans une logique dupliquee, c'est le moment de centraliser. Quand vous ajoutez une feature qui touche a une regle metier presente a plusieurs endroits, c'est le moment de refactoriser avant d'ajouter.
La dette technique DRY se rembourse incrementalement. Essayer de tout traiter en une fois produit des refactorings massifs difficiles a reviewer, risques de regression, et souvent abandonnes a mi-chemin.
Commencer par identifier les violations les plus couteuess : les regles metier que l'equipe modifie regulierement. Ce sont elles qui causent le plus de douleur et ou le benefice de la centralisation est le plus immediat.
Questions frequentes
DRY et WET, quelle est la difference ?
WET est un acronyme ironique qui signifie "Write Everything Twice" ou "We Enjoy Typing". Il designe les bases de code qui ne respectent pas DRY, avec de nombreuses duplications de logique. C'est souvent utilise pour decrire le resultat d'une croissance rapide sans refactoring regulier. WET n'est pas un principe a suivre, c'est une description d'un etat a eviter.
Faut-il toujours appliquer DRY dans les templates HTML ou CSS ?
En CSS, DRY s'applique bien via les variables CSS, les classes utilitaires, et les composants reutilisables. En HTML, les systemes de templates (Twig, Blade, Jinja2) permettent de centraliser les structures recurrentes via des includes ou des extends. Cela dit, la granularite compte : un composant trop generique avec trop de parametres peut devenir plus difficile a utiliser qu'un bloc HTML simple copie une fois. La pertinence depend du taux de reutilisation reel.
Comment detecter les violations DRY dans une base de code existante ?
Plusieurs approches complementaires : les outils de detection de code duplique comme phpcpd pour PHP ou jscpd pour JavaScript detectent les blocs de code similaires automatiquement. Les code reviews regulieres permettent de reperer les duplications par contexte metier, moins visibles aux outils. La recherche textuelle dans l'IDE sur des termes metier specifiques (noms de concepts, constantes) revele souvent des implementations paralleles. Enfin, les retours d'equipe lors des corrections de bugs ("j'ai du changer ca a trois endroits") sont des signaux concrets a noter et traiter.
DRY s'applique-t-il aussi a la documentation et aux commentaires ?
Oui, et c'est une dimension souvent negligee. Un commentaire qui explique ce que le code fait est une duplication de la connaissance que le code lui-meme devrait exprimer clairement. Les commentaires qui decrivent le pourquoi (contexte metier, contrainte externe, decision deliberee) ont de la valeur. Ceux qui decrivent le comment sont souvent le signe que le code gagnerait a etre renomme ou refactorie. La documentation externe dupliquant le comportement du code (sans generation automatique) est aussi sujette aux memes problemes de desynchronisation.
Est-ce que DRY s'oppose a la lisibilite du code ?
Bien applique, non. Une abstraction bien nommee qui encode une regle metier precise est souvent plus lisible que du code inline repetitif. Mais une abstraction prematuree ou mal nommee ajoute de l'indirection sans apporter de sens, ce qui nuit a la lisibilite. La cle est de s'assurer que chaque abstraction porte un nom qui communique son intention, pas seulement son implementation. Un service PricingService avec une methode calculateVolumeDiscount est lisible. Une fonction utilitaire generique calc avec six parametres booleens ne l'est pas, meme si elle elimine la duplication.
DRY est-il plus important dans certains types de projets ?
DRY prend de la valeur avec la taille du projet, la duree de vie du code, et la frequence des changements metier. Un script d'usage unique a peu besoin de DRY. Une application metier maintenue sur plusieurs annees par une equipe qui change a besoin de toute sa rigueur. Les projets avec des domaines metier complexes, des regles qui evoluent regularierement, ou des multiples points d'entree (API, CLI, queue worker) sont ceux ou les violations DRY coutent le plus cher et ou les benefices de son application sont les plus mesurables.


